
APIs and Advanced Analytics: Part 2
8 Good API design practices.

To realize the full benefits of the an API, it must be designed with developers and business objectives in mind. A well-designed API accelerates data availability, promote consistent integration, and ensure long-term maintainability of analytics workflows.
Part 1 of APIs and Advanced Analytics covered what APIs are, how they work and why they are foundational for integration, scalability, and real-time analytics.
In this Part 2, we cover eight best practices for API design, based on my experience. While this discussion is framed through the lens of advanced analytics, these practices apply broadly to API development in any context.
1. Choose the Right API Type
The type of API you choose has wide-ranging implications for data governance, rate limits, and how analytics systems access and consume data. Selecting the right API type ensures appropriate access control while optimizing for scalability and usability.
“Data governance is everything you do to ensure data is secure, private, accurate, available, and usable. It includes the actions people must take, the processes they must follow, and the technology that supports them throughout the data life cycle.” —Google Cloud
“Rate limiting is a strategy for limiting network traffic. It puts a cap on how often someone can repeat an action within a certain timeframe.”—CloudFlare
Each API type aligns with different audiences and use cases:
Private APIs are used internally within an organization to streamline internal workflows, promote modular architecture and support rapid iteration, expose data or services for internal use. For example, an internal API that streams production batch data into a forecasting engine or anomaly detection model.
Partner APIs are shared selectively with trusted external stakeholders such as logistics partners, collaborators, or vendors. These APIs typically include well defined governance rules and audit logging. For example, A 4PL (fourth-party logistics) API that allows warehouse partners to track inventory levels and update delivery schedules, enabling joint analytics on supply chain performance
Public APIs are open to external developers. These are normally used to support ecosystem growth and third-party innovation. It is good practice to design these kind of APIs with robust rate limiting, versioning, and security. For example, Zillow's Public Records API enables developers to build models that forecast housing trends.
Private APIs should also be designed with the potential to scale to partner or public access especially if your analytics application may later integrate across teams or organizations.
2. Choose the Right Architecture
“An API architecture is the framework of principles, practices, and patterns that guide the design, development, deployment, and maintenance of APIs”—sendbird
The architecture behind your API shapes how efficiently analytics systems can access, process, and respond to data. A good architecture balances performance, scalability, and flexibility of integration, especially as analytics needs evolve (e.g., from batch ETL to real-time inference). Choosing an architecture is not just a technical decision but a strategic one.
API architectures generally fall into two broad paradigms: request-response and event-driven. Understanding the differences between these paradigms is essential for building analytics systems that are responsive, scalable, and maintainable. Your choice of architecture is dependent and influences on how data is accessed, how often systems communicate, and how quickly insights can be delivered across analytics systems.
Request-response architectures
In these architectures, a client explicitly requests data or services, and the API returns a response. This is the most familiar pattern in analytics workflows and it is well-suited for retrieving historical data, running on-demand queries, or pulling model outputs.
The most common implementation of this kind of architecture is REST (REpresentational State Transfer): it is a stateless protocol that uses standard HTTP methods to exchange data—usually in JSON format—which makes it highly compatible with analytics tools.
GraphQL is a newer but increasingly popular request-response architecture that offers more flexibility than REST. Rather than receiving a full response payload (which might include unused fields), clients using GraphQL can request only the exact data they need. This is particularly helpful in analytics systems that deal with large or nested datasets, such as metadata registries or feature stores. For example, a model registry dashboard might use GraphQL to query only the training date and model accuracy without loading the entire model object.
For hight performance internal systems, gRPC is an efficient alternative to REST. It is built on HTTP/2 and uses binary serialization via protocol buffers. gRPC excels in environments where speed and resource efficiency are important. In analytics, this is particularly useful for deploying machine learning inference services that need to serve predictions at scale with minimal latency.
SOAP is a less common architecture in modern analytics systems, yet it remains relevant in legacy (read older) enterprise environments. SOAP is lightweight for exchange of information in a decentralized distributed environment (see some simple examples here). SOAP uses XML-based messaging and is highly structured, supporting features like strict authentication, encryption, and transactional integrity. For example, if you are pulling patient data from an electronic health record (EHR) system for predictive modeling or compliance reporting, SOAP may still be the only available interface.
Event-driven architectures
In contrast to the request-response architectures, event-driven architecture operate by pushing data to subscribers when when specific events occur. This architecture supports real-time workflows and it is popular in analytics pipelines that require urgent reaction.
Webhooks is common event-driven architecture. With webhooks, systems can notify one another immediately when a triggering event happens. For example, a webhook can notify an analytics system when new sensor data is logged in a production environment, prompting an automated update of a predictive maintenance model.
3. Design for Easy Use and Consistency
Whether your API serves internal data scientists or external partners, usability and consistency are key to driving adoption and maintaining stable analytics workflows over time. APIs should be intuitive to learn, predictable in their behavior, and standardized in their conventions to reduce friction during integration.
In my work, I have applied these principles specifically to REST APIS. The examples in this section are drawn from two REST APIs I have developed for the Birkin Analytics platform: (1) the
birkin-backend, a Node.js + Express API that powers the frontend, and (2) thebirkin-engine,a FASTAPI service that handles various analytics logic. While these implementations follow the RESTFul architecture, the broader principle of designing for clarity and consistency applied across API architectures.
To make your API more intuitive for developers, a good starting point is to follow established conventions, assuming that developers are familiar with standard practices. In the RESTful paradigm—which I have used exclusively in my work—resources are identified using URIs (Uniform Resource Identifiers), and these should be expressed as nouns (e.g., /users, /products). Resource names are typically plural to represent collections. REST also relies on HTTP methods like GET, POST, PUT, and DELETE to define the intended action, making the interface both expressive and predicable.
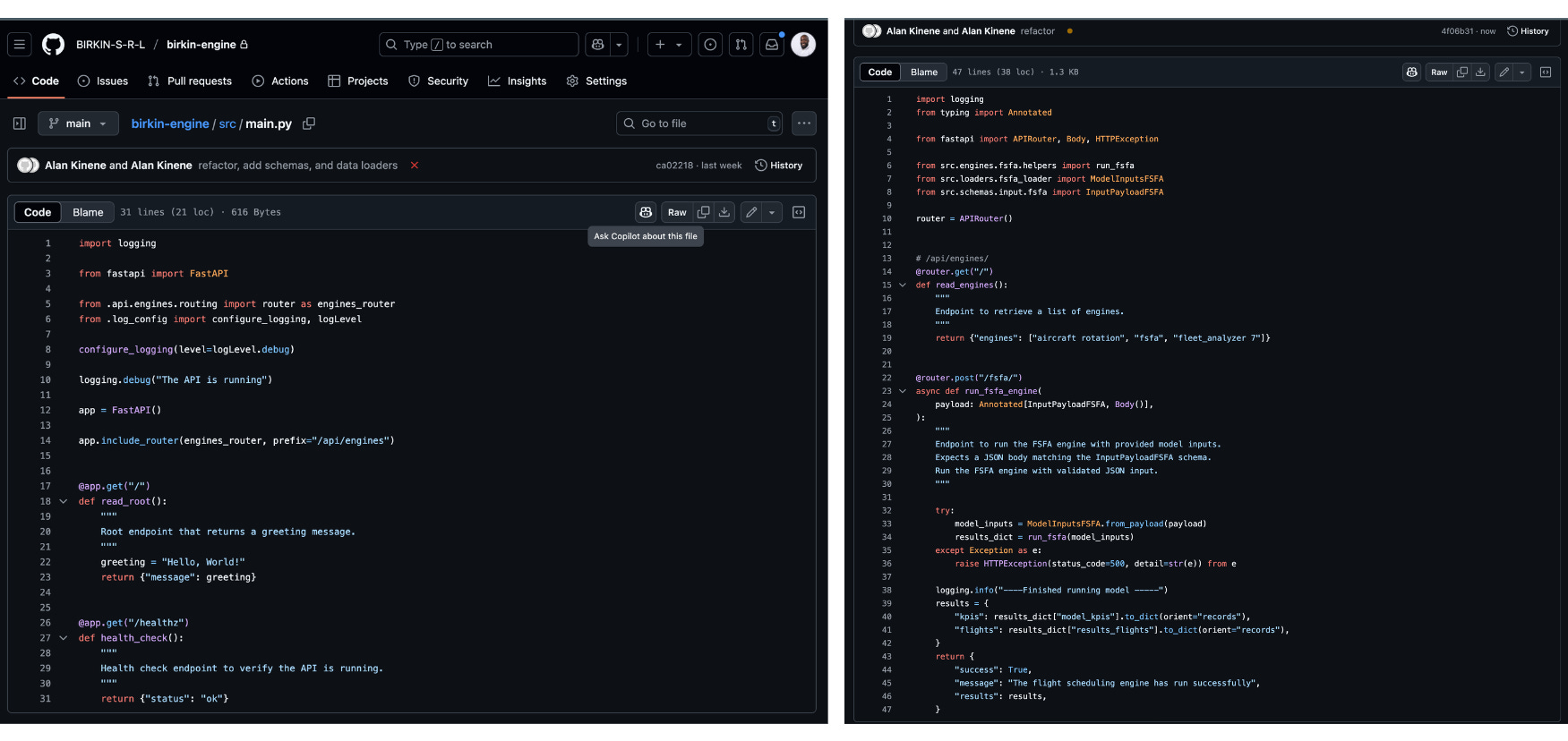
GET and POST clearly define the actions for retrieving a list of engines or running the scheduling engine. Here, I follow snake_case naming convention.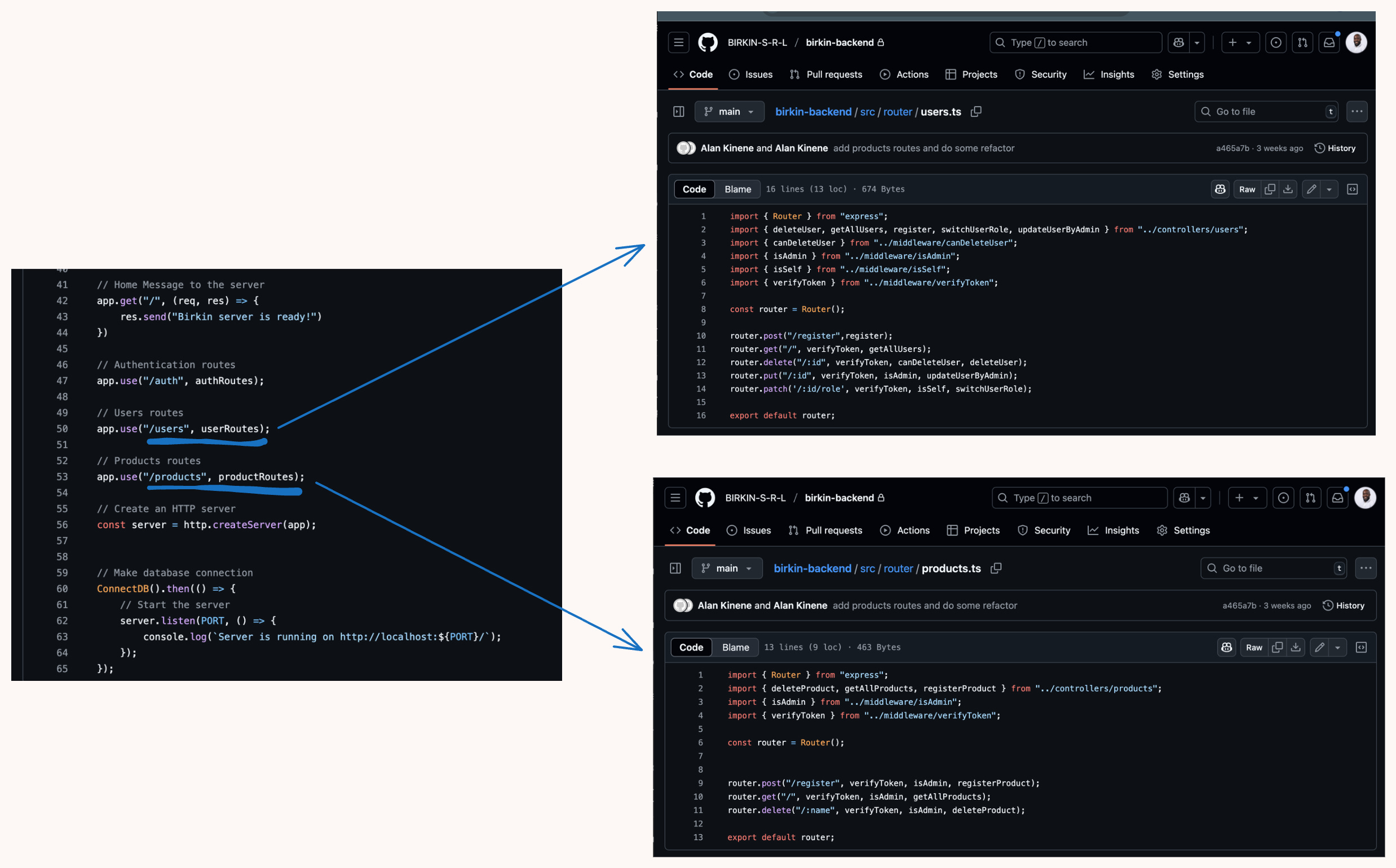
Node.js + Express) following RESTful conventions: This snippet shows how the birkin-backend organizes its API routes using modular Express routers, with pluralized resource paths such as /users and /products. The HTTP method verbs used include POST, GET, PUT, and DELETE. Beyond route structure, consistency in naming conventions and formatting is just as important as following established REST principles. It is important to use the same casing style (e.g., snake_case, camelCase) across all fields in your API responses and request payloads. Inconsistencies, especially when mixing styles between endpoints or across query parameters and JSON bodies, can lead to confusion and bugs in downstream analytics workflows. Similarly, adopting a standard date and time format such as ISO 8601 (2025-08-01T13:45:30Z) ensures that dates are easy to parse, are timezone-aware, interoperable across systems.
Another way to ensuring easy use is by returning predictable and uniform response structures. Clients should not have to guess whether a field will be missing or nested differently across endpoints. One simple but effective pattern is to always wrap responses in a common envelop: this simplifies error handling and debugging as well as enables standardized parsing in analytics tools.
Larger platforms like Uber use this structure consistently across their APIs, which makes it easier for partners to build analytics dashboards that automatically detect and visualize operational data from standardized responses.( Have a look at the Uber API Docs).
4. Versioning to Avoid Breaking Changes
APIs evolve. When they do, unannounced changes to a response structure or schema can silently break downstream analytics workflows—whether it’s a daily forecasting job, a production ETL pipeline, or a dashboard refresh. To prevent this, it’s essential to version your API, starting from day one.
A common approach is to include the version in the URL path (e.g., /api/v1/). This method is simple, transparent, and widely understood. It ensures that breaking changes (e.g., renaming fields, changing response formats) won’t affect clients still relying on earlier versions. More granular control can be achieved by using semantic versioning (semver)—expressed as v<MAJOR>.<MINOR>.<PATCH>—especially for internal APIs used in analytics workflows where updates are frequent but backward compatibility is critical.
In my own projects, I’ve implemented basic versioning using path prefixes like /api/v1/, which can be seen in both birkin-backend and birkin-engine. My current thinking is to manage more complex versioning strategies at the deployment level. Just like we expose development and production environments using subdomains, we could expose versioned APIs this way as well (e.g., api.birkinanalytics.org/v1, api.birkinanalytics.org/v2). This has the advantage of isolating versioned deployments entirely, making it easier to test or migrate without interrupting dependent systems.
I’m curious how others are handling this. Do you manage versioning purely in the URL path? Use headers? Or split versions across deployments? Let me know—I’d love to learn how different teams are approaching versioning in analytics contexts.
5. Provide Metadata and Documentation
Good API design doesn’t stop at delivering the right data—it also provides the context needed to interpret and use that data effectively. This is where metadata and documentation play a crucial role. In analytics workflows, where APIs feed directly into models, dashboards, or ETL pipelines, missing context can be just as problematic as missing data.
At a minimum, every API response should include relevant metadata—such as the total number of records available, the current page number, and, if applicable, the version of the schema being returned. For example, if your analytics script fetches paginated production data, knowing whether you’re on page 1 of 1 or page 1 of 10 determines whether the process has all the data it needs. Including a schema version in the response or headers also helps downstream systems adapt gracefully to future changes.
Equally important is comprehensive, machine-readable documentation. Tools like Swagger allow you to automatically generate interactive documentation that lists available endpoints, required parameters, request/response examples, and error codes. This lowers the barrier for analytics teams to integrate with the API quickly, without having to guess data shapes or reverse-engineer payloads. In larger organizations, well-documented APIs also make it easier to maintain consistent standards across teams and services.
Google Cloud’s API design guidelines emphasize self-documenting APIs for data consistency across analytics workflows.
See an example of Uber’s documentation here.
6. Test and Monitor for Reliability
Just like any other code, APIs should be tested and monitored to ensure they behave as expected in both development and production environments. Unit tests verify that individual functions and endpoint logic return the correct outputs and structures. Integration tests go further to confirm that different parts of the system—such as database connections, authentication flows, or external services—work correctly together. Other kinds of tests include (check out this blog and this one). For analytics workflows, tests protect against subtle failures that could silently propagate incorrect or incomplete data to dashboards or models.
In production, monitoring becomes critical. Tracking metrics such as latency, error rates, and endpoint usage allows teams to detect regressions in performance, tune analytics ingestion rates, and proactively address failures.
At a company like Airbnb, for example, analytics engineers can monitor the uptime and latency of internal feature store APIs that feed directly into their machine learning models—ensuring predictions are both accurate and timely.
7. Support Pagination, Filtering, and Sorting
To make APIs more efficient and analytics-friendly, it’s essential to support common data access patterns like pagination, filtering, and sorting:
Pagination helps clients avoid retrieving large datasets all at once using query parameters such as
?limit=100&offset=0.Filtering enables more targeted queries, such as
?filter=region:us-west, reducing data processing overhead.Sorting (e.g.,
?sort=timestamp:desc) is particularly important for time series pipelines that depend on temporal order for aggregation or modeling.
From an analytics perspective, these features are not just nice-to-have—they’re critical. Without pagination, large API calls can time out or overload clients. With filtering, models receive cleaner, more relevant input data. Supporting these options improves performance of analytics systems built on top of the API.
8. Secure and Govern Data Access
Lastly, as APIs become central to analytics platforms, ensuring secure and compliant data access is non-negotiable. Implementing authentication mechanisms like OAuth2, API keys, or JWTs (JSON Web Tokens) helps ensure that only authorized users can access your API. Adding role-based access controls further protects sensitive data, allowing different users or systems to see only what they’re permitted to.
In analytics settings—especially those involving personal, health, or financial data—logging and auditing API usage is critical to meeting compliance standards like HIPAA or GDPR. For example, a financial institution might allow analysts to access only aggregated, anonymized data through secured endpoints while restricting raw account-level data to admins. These safeguards not only build trust but ensure that analytics systems are legally and ethically sound.
References
Swagger. Best Practices in API Design. https://swagger.io/resources/articles/best-practices-in-api-design
Microsoft Azure. API Design Best Practices. https://learn.microsoft.com/en-us/azure/architecture/best-practices/api-design
Design Gurus. 10 Best API Design Practices. https://www.designgurus.io/blog/10-best-api-design-practices
Wahab2 Blog. API Architecture Best Practices for Designing REST APIs. https://blog.wahab2.com/api-architecture-best-practices-for-designing-rest-apis-bf907025f5f